|
Step-by-step tutorial
This tutorial describes step-by-step how you can work with Similarity in the fastest and the most effective way. The most advanced and powerful function of Similarity is its search of duplicate music and image files, so it is this function that we focus on in this article. Notice, we do not review all and every function of the program, including the advanced audio analysis, tag editor, etc. To learn more about these functions, please refer to the FAQ, help system or other articles at our website.
This tutorial consists of 3 sections. The first section uses the default settings and doesn’t need additional configuration (suits for small collections with no more than 10,000 files). The second section is intended for the case when you want to compare your collection with a number of files you potentially would include to it. This may require adjusting program’s settings. The third section is for large and extra large collections (over than 30,000 files) that requires precision adjustments and understanding of some specifics.
Part 1
Let’s first see what our problem is. We have folders containing many music files – files we industriously gathered all over the Internet for months – and now it would be great to bring some order to this music file chaos. First of all, let’s find duplicates in these folders and delete them.
-
Run Similarity. Upon startup you should an Explorer-like window with its left panel containing folders, and its right panel displaying the contents of those folders.
The lower left corner shows currently selected folders and is empty upon startup.
-
Now in the left panel with a folder tree find your folders with music, images and select them with check marks.
It is worth mentioning, that you can easily use your network folders, removable devices, entire disks or even Windows 7 libraries.
-
If you done everything right, the bottom left pane will display your current selection. If necessary, you can remove any of them from here with a right-click menu.
-
Now the tricky part. Find the "Play" button on the toolbar and click it.
The scan process should run. If everything is going right, you should see constantly changing numbers indicating the amount of scanned files and the overall progress.
The scan results are displayed in real time, so you can start working with them right away, but for the purpose of this tutorial we will wait until the process finishes.
By the way, Premium version can interrupt the scan process at any time saving the current progress. On the next run, the application will continue the scan from the point it stopped the last time. The free version users probably shouldn’t interrupt the scan process, or they’ll have to restart it from the beginning. But even in this case the subsequent scan will be much faster thanks to the advanced cache system implemented in the program.
-
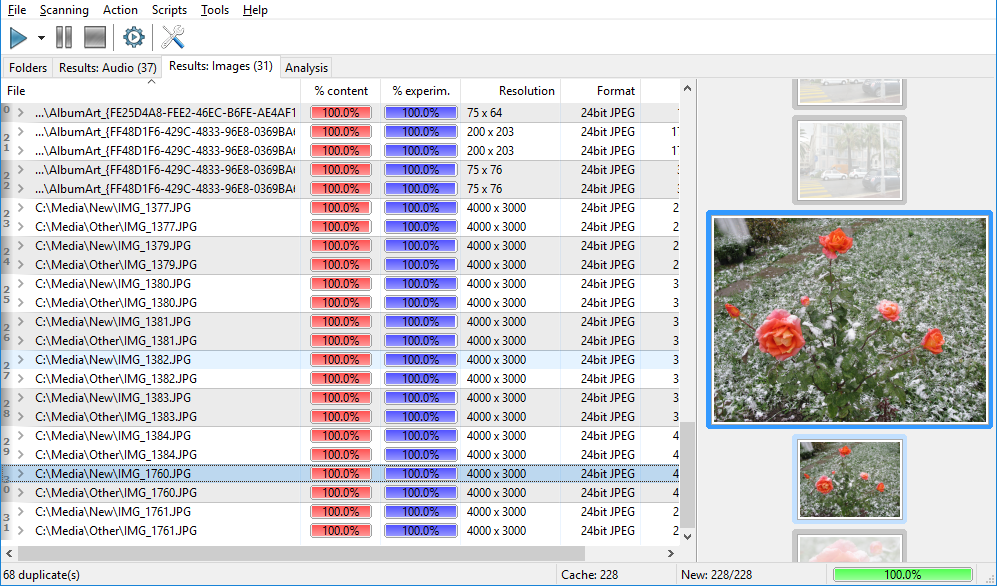
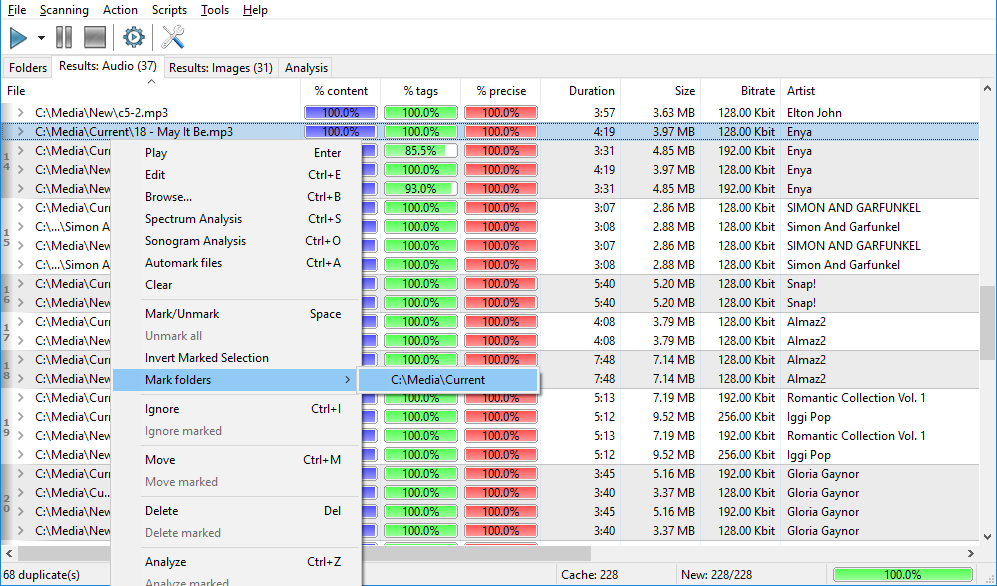
Once the scan finishes, switch to the "Results" tab. A number in parenthesis near the tab name is the amount of duplicate groups. The window itself shows this groups, to learn how groups are built, please refer to this article.
-
Let’s start working with duplicates. Similar files are gathered into groups of duplicates, you can distinguish the groups by color and a vertical number at the left.
For easier processing, you can sort doubles by any given property, both ascending and descending. Note that sorting goes in two stages: first all files in a group are sorted, then groups themselves are sorted too based on their first files. You can read more detailed explanation of the process here.
-
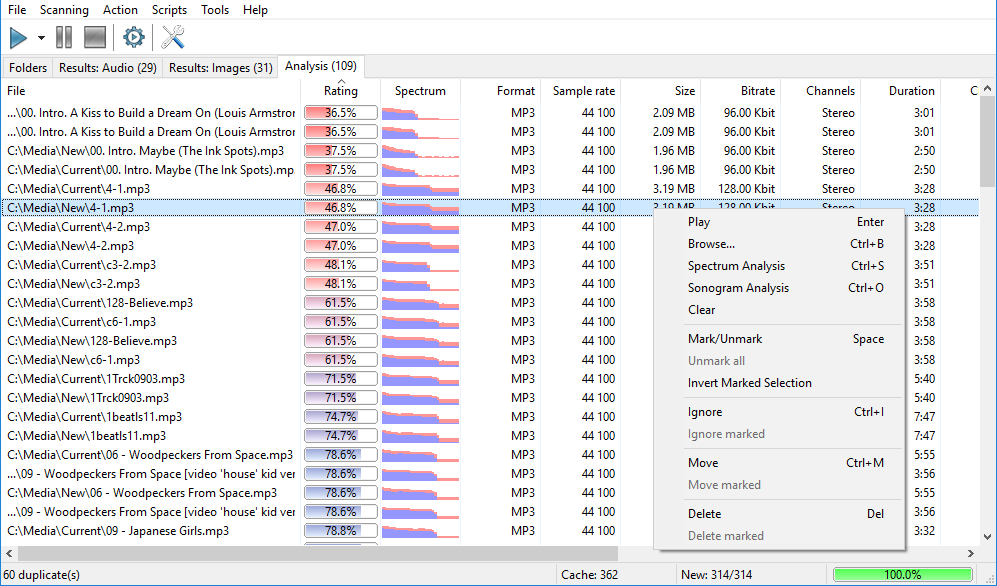
Now you can analyze the quality of files to make it easier to select best/worst files in a group. Note that this is not obligatory, so if you experience no problems finding the best composition in a group, just skip to next step, also note, quality analysis may take significant time. In the context menu or in the main menu click "Analyze all".
The analysis will run and will scan all files from the duplicates list. Wait for the process to finish. The information about files being analyzed is displayed in real-time at the ‘Analysis’ tab. If you want to learn more about these parameters, please refer to this article.
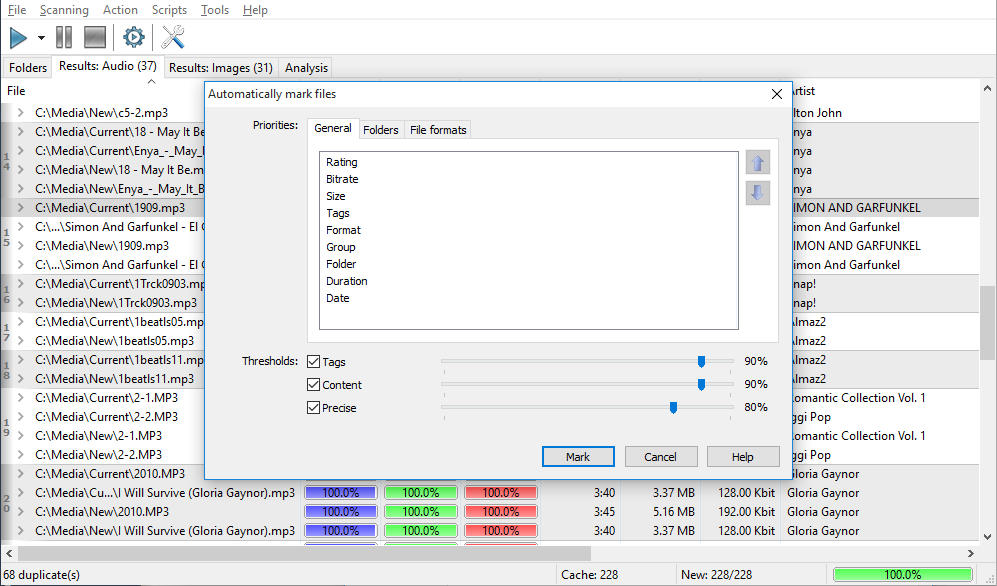
After the analysis completes, the "Rating" column is displayed. This column characterizes file’s quality. The higher the value here, the higher the quality of the file is. Further, you can use information from this column in the Auto-mark dialog (available in the Premium version only) or any time you need to make a decision.
-
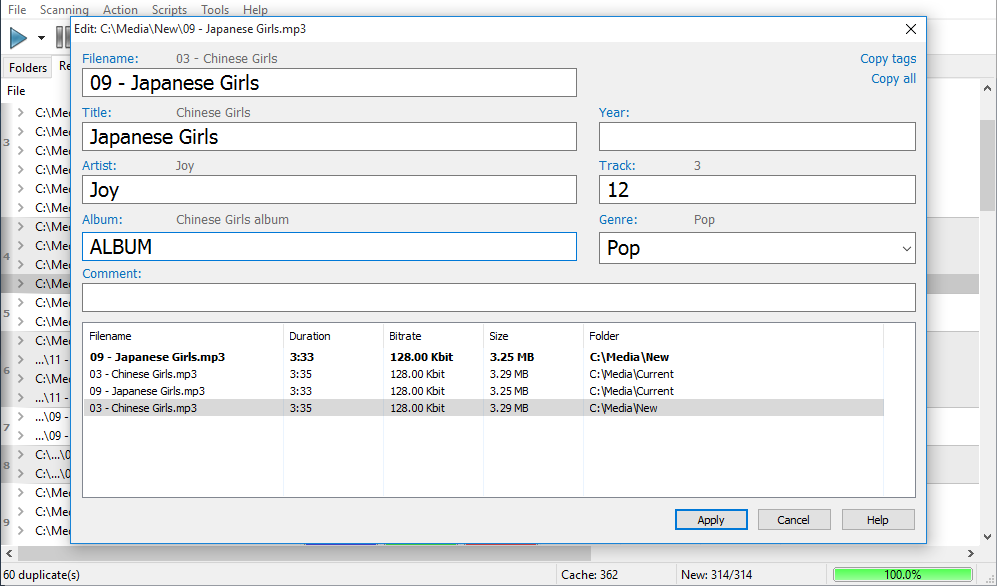
You have two ways here: you can either manually review each file and decide whether or not you want to keep it, or use the "Automark files" command that does all the work automatically.
This function is only available in the Premium version. Select this function, set desired criteria for the quality of a file and threshold values (to avoid mistakenly marked similar yet not duplicate files) and click the "Mark" button, find more details here. This function doesn’t perform automatic deletion of files; it merely marks the worst files of all duplicates in a group. An action to be applied to these files is up to you.
Now let’s see how this works in the manual mode. The main operations over files are performed via the right-click menu or with keyboard shortcuts. The list supports multiple selection – use Ctrl/Shift and your mouse to select several files and apply the same operation to all of them. To mark a file, use the corresponding command in the right-click menu – "Mark/Unmark".
-
Let’s go back to the deletion. After we have marked files either automatically or manually, we should delete them. This is easy: use the
right-click menu again and select "Delete marked", then confirm the deletion. All files will be moved to Recycle Bin and simultaneously
they will disappear from the corresponding groups in the result window.
Continue with the rest of doubles the same way.
Part 2
We won’t explain the work with functions of the program in all details, as we suppose a user has already taken a look to the FAQ, help system. The method described below only work in the Premium version.
So, let’s say we have faced the following problem: we have old and trusted collection of music files checked all over and we don’t want to change anything in it; and we have a new set of music compositions we would like to include to our collection, but we want to check, if we already have some of them in the collection. Also, we’re very busy men, so we don’t waste time filling tags and all that stuff, so comparing by tags is meaningless in this case, so we should turn it off. We want to see only true duplicates in the results and not files that just similar to ours. Ok, let’s start:
-
Run Similarity
-
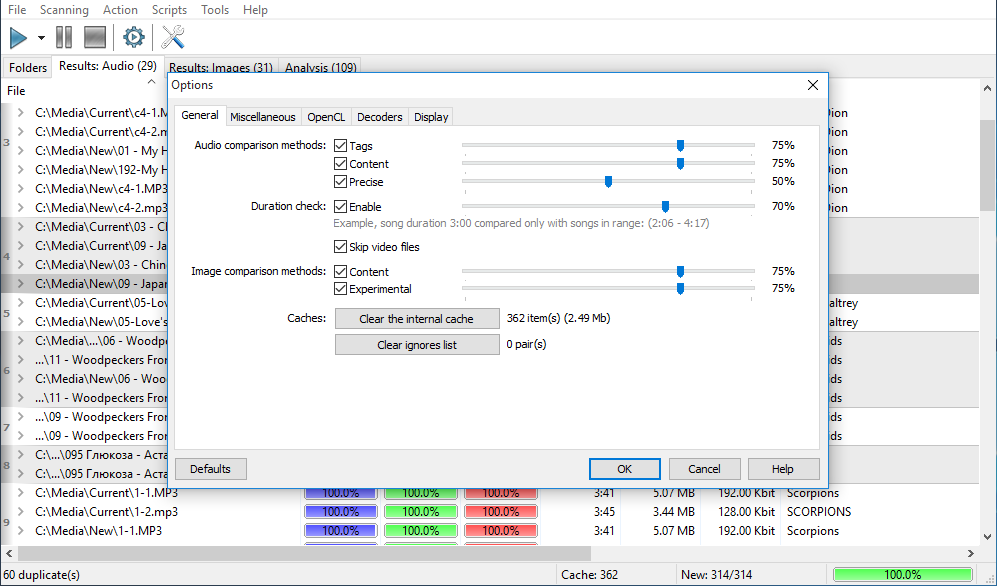
Bring up the "Options" window and turn off the comparison by tags option. Then, move threshold sliders of the rest two algorithms to 90.
-
Select folders with our collection and a folder with new files.
-
In the selected files list use the right-click menu to mark folders of our collection as group #1 and a new files folder as #2.
This function is only available in the Premium version; you can’t do this in the free version.
-
Run the scan process.
-
The rest of the actions are performed the way they are described in the part 1.
Part 3
Now let’s take a look at the case where your collection contains a big number of files, over 30,000. The crucial point to consider here is memory consumption, it is proportional to the number of files being compared, so we recommend to use the 64-bit version of Similarity, especially if you need to process more than 100,000 files. The method described below only work in the Premium version.
-
Run Similarity
-
Bring up the "Options" window and turn off the comparison by tags option and content option. This is necessary, because tag comparison can lead to many false positives which leads to creating and merging of groups like a snowball, which in turn makes it harder to work with the program and impairs visual acceptability. This is also true for the old content based algorithm – its precision is not enough, besides, by turning off this algorithm, memory consumption decreases almost twice, because it won’t be requiring cache anymore. The only truly efficient algorithm for such enormous amounts of files to compare is the ‘Precise’ algorithm. You will need to set its threshold to 85-95% (adjust the value if the comparison accuracy drops). Alternatively, you can leave the other two algorithms, but increase their thresholds up to 95-100%.
-
Select folders with your collections.
-
Run the scan process.
-
The rest of the actions are performed the way they are described in the part 1.
Finally, we learned to limit the scope of a scan – only files from different groups are compared with each other. This is utterly convenient to compare your old collection with some additions of potentially new files. Also, we have turned off comparing by tags, because tags may be filled in incorrectly, or isn’t set at all. You can also disable the old content based comparison algorithm to work with huge collections. Another helpful feature is adjusting threshold values which allows setting stricter or more soft compare conditions for the files to be considered as duplicates.
|
|
Downloads
Premium version
Latest news
|